

Stable Diffusion 主要功能:
Ai游戏软件Stable Diffusion 图文介绍:

Stability AI推出的文本到图像生成AI模型
Stable Diffusion 是一款免费、开源的人工智能图像生成器。以下是关于它的详细介绍:
发展历程:
2022 年 8 月推出,由 Stability AI 公司研发。
2022 年 11 月推出 sd2.0 版本。
2023 年 6 月推出 sdxl0.9 版本更新,其具备一个 35 亿参数的基础模型和一个 66 亿参数的附加模型,能够创建深度更广、分辨率更高的逼真图像。
2024 年 2 月 22 日,发布了 Stable Diffusion 3 早期预览版。
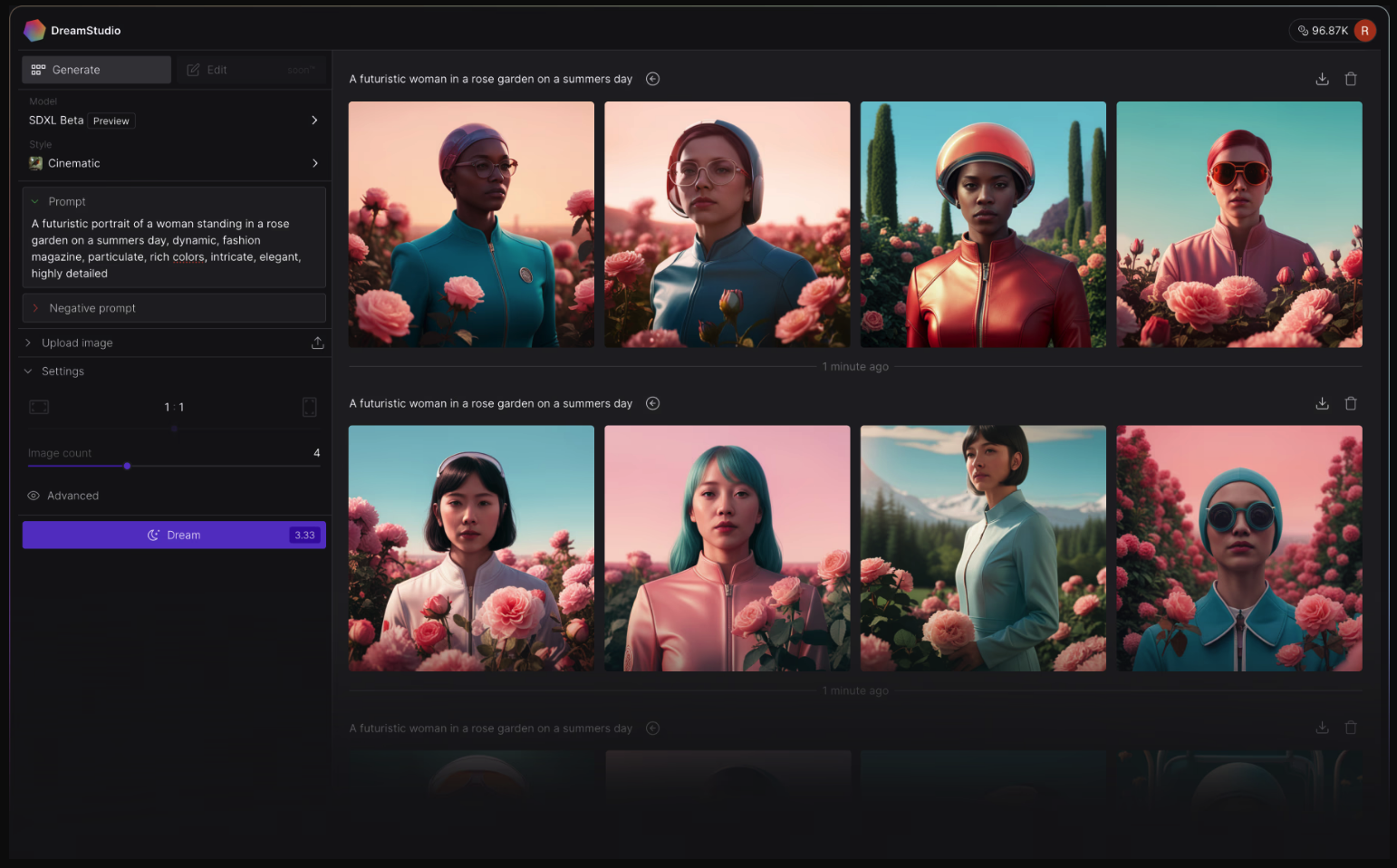
技术原理:
Stable Diffusion 是一种潜在扩散模型,属于深度生成式人工智能神经网络。它通过学习大量的图像数据,理解文本描述与图像之间的关联,然后根据输入的文本提示生成相应的图像。在生成过程中,模型会逐步添加噪声并逆向去除噪声,以生成最终的图像。
功能特点:
高质量图像生成:能够生成高分辨率、逼真的图像,具有出色的细节和真实感。
稳定性高:与其他深度学习模型相比,在训练过程中更不容易出现崩溃或模型不稳定的情况。
灵活性强:用户可以通过输入详细的文本描述,包括场景、物体、风格、颜色等各种元素,来控制图像的生成内容。
多领域应用:除了图像生成,在语音处理、自然语言处理等多个领域也有应用潜力。
应用领域:
艺术创作:为艺术家提供了新的创作工具和灵感来源,帮助他们快速生成创意概念图、插画、漫画等。
游戏开发:用于生成游戏中的角色、场景、道具等图像资源,提高游戏开发效率。
电影特效:可以制作电影中的特效场景、虚拟角色等,降低特效制作成本。
广告设计:协助设计师快速生成广告宣传图、海报等设计作品。
医学图像处理:如辅助医疗影像的分析、病变区域的识别等。
使用方式:
用户需要在支持 Stable Diffusion 的平台或软件上进行操作。首先输入描述性的文本提示,然后设置相关的参数,如生成图像的尺寸、迭代步数、随机种子等,最后点击生成按钮,模型就会根据输入的信息生成相应的图像。
争议与挑战:
版权问题:由于生成的图像是基于训练数据学习得到的,可能存在与现有作品相似的情况,引发版权争议。例如,2023 年就发生了首例 AI 生成图侵权案。
伦理道德问题:可能被用于不道德或不合法的目的,如生成虚假的新闻图片、恶意的宣传图像等。
技术局限性:对于复杂的文本提示理解可能不够准确,生成的图像可能与用户的预期存在一定偏差。并且在生成一些特定主题的图像时,可能会受到训练数据的限制,出现偏差或不适当的内容。
本网站(AIGC官网)刊载的所有内容,包括文字、图片、音频、视频等均在网上搜集。
访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。除此以外,将本网站任何内容或服务用于其他用途时,须征得本网站及相关权利人的书面许可,并支付报酬。
本网站内容原作者如不愿意在本网站刊登内容,请及时通知本站,予以删除。
相关导航

使用AI技术快速生成和编辑高质量图片。