
首页 > 教程 > AI模型 国际崭露锋芒 国内模型竞相发布
AI模型 国际崭露锋芒 国内模型竞相发布
发布时间:2023-11-25 11:57:12 | 责任编辑:字母汇 | 浏览量:522 次
主要参与的公司和研究机构
- OpenAI
作为GPT系列模型的开发者,在市场上具有显著竞争优势。GPT-4在各种专业测试和学术基准上的表现与人类水平相当。 - Google
发布了第二代大语言模型PaLM 2,基于新训练模型升级而来的生成式AI Bard,以及集成了生成式AI能力的“试验版”谷歌搜索以及智能云等产品。 - Meta AI
开源大语言模型LLaMA,可以在单个GPU上运行。 - 微软
推出New Bing,并将AI能力与旗下产品进行广泛整合。将基础模型与数以百万计的现有模型和系统API 进行整合。 - 其他研究机构斯坦福:语言模型Alpaca仅用52K的数据指令达到良好效果;MIT:大模型LAMPP用于视觉感知和推理任务。
主要特点
技术创新和竞争
- 模型性能:关键竞争因素在于如何在确保性能的基础上,减少训
练和推理的成本。 - 数据安全与隐私:企业应重视此类技术创新,例如差分隐私和联
邦学习等。 - 可解释性:对于建立用户信任和确保模型可靠性至关重要。
- 模型泛化能力:提升模型在多种语言、领域和任务方面的适用性,
以满足更广泛的应用需求。
应用领域和商业模式
- 企业服务:大型语言模型在企业服务中的应用涵盖了客户支持、市场推广和内容创作等。
- 用户体验:语言模型可为用户提供智能助手、教育辅导等服务。• 开发者工具:OpenAI的GPT系列模型等技术已在这方面得到广泛应用。
政策和法规
- 数据隐私法规:随着GDPR等数据隐私法规的实施,大型语言模型在数据处理方面需要遵循更为严格的规定。
- AI伦理:AI伦理问题(如算法歧视、非道德内容生成等)对大型语言模型的应用和发展产生了影响。
合作和竞争
- 行业合作:为了应对共同的挑战,例如数据隐私、AI伦理等,不同公司和研究机构可能会开展合作。
- 市场竞争:市场上的主要参与者将在技术、应用和商业模式等方面展开竞争,以争夺市场份额和用户满意度。
LLaMA模型:开源巨头共享生态
LLaMA是Meta开源的大规模语言模型,参数量从70亿到650亿不等,训练使用多达14000亿tokens语料。LLaMA在常识推理、问答、数学推理、代码生成、语言理解等能力上都有优异的表现,而且可以在单个GPU上运行。是最有安卓像的开源生态。
 经过斯坦福大学研发的创新模型Alpaca,在基于Meta的LLaMA微调之后,其表现已基本与GPT3.5相媲美。令人瞩目的是,该模型仅利用了52k数据进行训练,训练成本仅需600美元。
经过斯坦福大学研发的创新模型Alpaca,在基于Meta的LLaMA微调之后,其表现已基本与GPT3.5相媲美。令人瞩目的是,该模型仅利用了52k数据进行训练,训练成本仅需600美元。
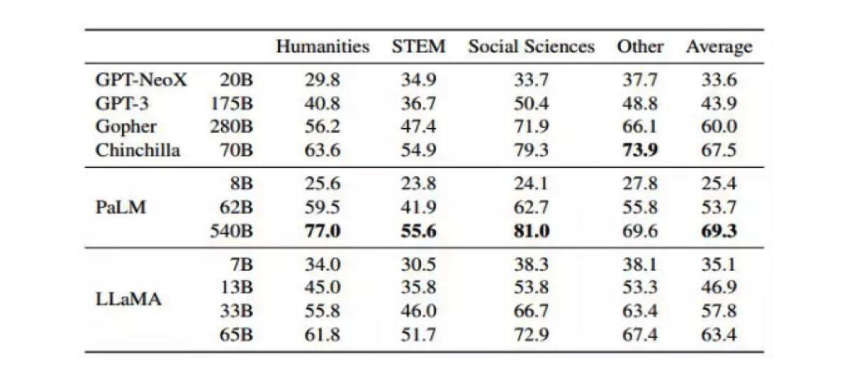 2023年2月28日,Meta Platforms展示了LLaMA在人文社会学科、科学、技术等领域的多项选择题测试成果。
2023年2月28日,Meta Platforms展示了LLaMA在人文社会学科、科学、技术等领域的多项选择题测试成果。
- ] 标准化:在每个transformer层输入前进行标准化,提高训练稳定性
- ] SwiGLU激活函数:在Feedforward层使用Gated Linear Units和
- SwiGLU激活函数,模型非线性能力和选择性强劲
- ] 旋转位置编码:将位置信息编码为高维空间中的旋转变换,可以保持
- 相对位置关系的不变性
- ] 多语言能力:使用通用的词汇表和分词器,适应多样化的语言环境
- ] 多元适应:具备了多语言和多编码能力。通过prompt和示例来适应
- 不同的任务和领域
- ] 深度理解:在常识推理、问答、数学推理、代码生成、语言理解等能
- 力上都有优异的表现
- ] 智能翻译:将人类语言转换为SQL查询或代码生成
- ] 知识融合:从大量的文本数据中提取和融合知识,实现对文本信息的
- 深入理解和分析,例如解释笑话、零样本分类或数学推理
国内模型:竞相发布支持并进
- 百度:文心一言
- 华为:盘古
- 360:360智脑
- 科大讯飞:星火认知
- 阿里巴巴:通义千问
- 腾讯:混元
- 商汤科技:日日新
- 澜舟科技:孟子
- 智源研究院:悟道2.0
- 昆仑万维:天工3.5
- 清华大学 ChatGLM-6B
- 复旦大学:MOSS
- 中科院自动化所:紫东太初
- 面壁智能:CPM-Bee
- 达观数据: 曹植
©️版权声明:
本网站(https://aigc.izzi.cn)刊载的所有内容,包括文字、图片、音频、视频等均在网上搜集。
访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。除此以外,将本网站任何内容或服务用于其他用途时,须征得本网站及相关权利人的书面许可,并支付报酬。
本网站内容原作者如不愿意在本网站刊登内容,请及时通知本站,予以删除。
本网站(https://aigc.izzi.cn)刊载的所有内容,包括文字、图片、音频、视频等均在网上搜集。
访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。除此以外,将本网站任何内容或服务用于其他用途时,须征得本网站及相关权利人的书面许可,并支付报酬。
本网站内容原作者如不愿意在本网站刊登内容,请及时通知本站,予以删除。
上一篇: 怎么用AIGC去赚到“第一桶金”