
Meta 推出 Multi-SpatialMLLM:革新多模态 AI 空间认知的先锋
发布时间:2025-05-29 14:57:39 | 责任编辑:张毅 | 浏览量:279 次
《Meta 推出 Multi-SpatialMLLM:革新多模态 AI 空间认知的先锋》相关软件官网
科技巨头 Meta 与香港中文大学的研究团队联合推出了 Multi-SpatialMLLM 模型,这一新框架在多模态大语言模型(MLLMs)的发展中取得了显著进展,尤其是在空间理解方面。该模型通过整合深度感知、视觉对应和动态感知三大组件,突破了以往单帧图像分析的限制,为更复杂的视觉任务提供了强有力的支持。
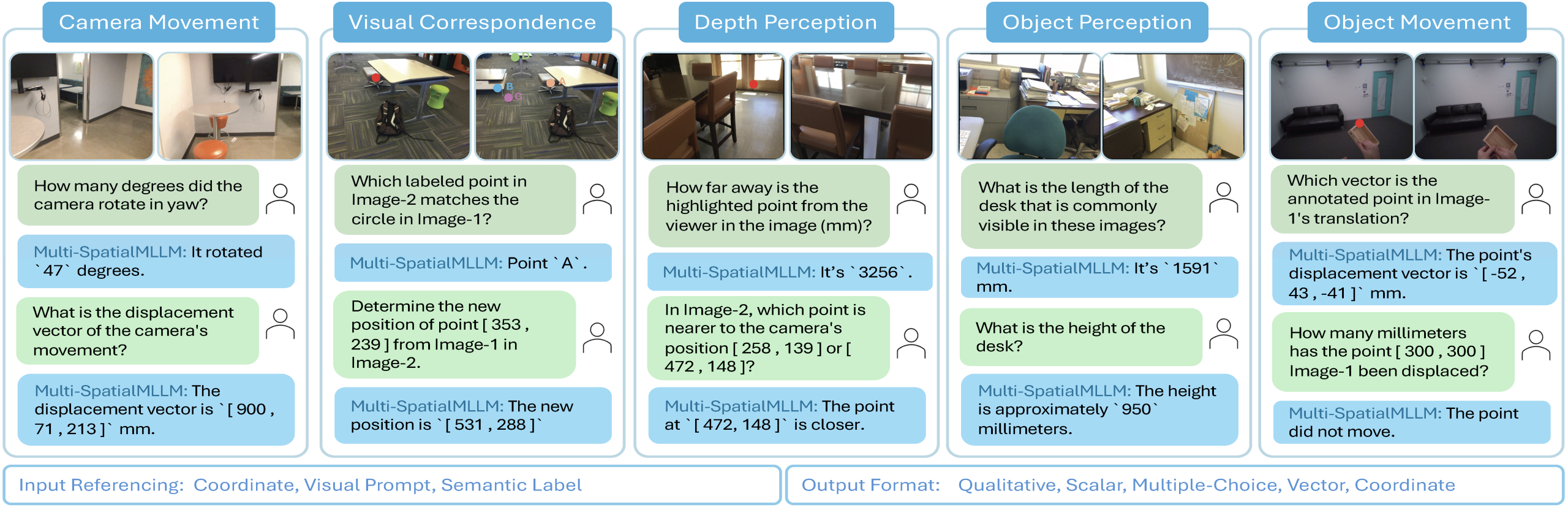
近年来,随着机器人和自动驾驶等领域对空间理解能力的需求不断增长,现有的 MLLMs 面临着诸多挑战。研究发现,现有模型在基础空间推理任务中表现不佳,例如,无法准确区分左右方向。这一现象主要源于缺乏专门的训练数据,且传统的方法往往只能基于静态视角进行分析,缺少对动态信息的处理。
为了解决这一问题,Meta 的 FAIR 团队与香港中文大学共同推出了 MultiSPA 数据集。该数据集覆盖了超过2700万个样本,涵盖多样化的3D 和4D 场景,结合了 Aria Digital Twin 和 Panoptic Studio 等高质量标注数据,并通过 GPT-4o 生成了多种任务模板。
此外,研究团队设计了五个训练任务,包括深度感知、相机移动感知和物体大小感知等,以此来提升 Multi-SpatialMLLM 在多帧空间推理上的能力。经过一系列测试,Multi-SpatialMLLM 在 MultiSPA 基准测试中的表现十分优异,平均提升了36%,在定性任务中的准确率也达到了80-90%,显著超越了基础模型的50%。尤其是在预测相机移动向量等高难度任务上,该模型也取得了18% 的准确率。
在 BLINK 基准测试中,Multi-SpatialMLLM 的准确率接近90%,平均提升了26.4%,超越了多个专有系统。而在标准视觉问答(VQA)测试中,该模型也保持了其原有的性能,显示了其在不依赖过度拟合空间推理任务的情况下,依然具有良好的通用能力。
划重点:
🌟 Meta 推出的 Multi-SpatialMLLM 模型显著提升了多模态大语言模型的空间理解能力。
📊 新模型通过整合深度感知、视觉对应和动态感知三大组件,克服了单帧图像分析的局限。
🏆 Multi-SpatialMLLM 在多项基准测试中表现优秀,准确率大幅提升,超越传统模型。
论文:https://modelscope.cn/papers/2505.17015
GitHub

Meta公司与香港中文大学联合推出了Multi-SpatialMLLM模型,这一多模态大语言模型在空间理解方面取得了显著进展,标志着多模态AI空间理解能力的重大突破。
研究背景
多模态大语言模型(MLLMs)在视觉任务处理上已取得显著进展,但现有模型大多只能处理单帧图像,缺乏动态信息处理能力,导致在基础空间推理任务中表现不佳,例如无法准确区分左右方向。随着机器人和自动驾驶等领域对空间理解能力的需求不断增长,这一局限性成为亟待解决的问题。
研究方法
为解决这一问题,Meta的FAIR团队与香港中文大学共同推出了MultiSPA数据集,该数据集包含超过2700万个样本,涵盖多样化的3D和4D场景,结合了Aria Digital Twin、Panoptic Studio等高质量标注场景数据,并通过GPT-4o生成了多样化的任务模板。基于此数据集,研究团队设计了五个训练任务,包括深度感知、相机移动感知和物体大小感知等,以提升Multi-SpatialMLLM模型在多帧空间推理上的能力。
实验结果
在MultiSPA基准测试中,Multi-SpatialMLLM模型的平均准确率达到56.11%,相比基础模型提高了35.68个百分点。特别是在定性任务上,如深度比较、相机方向和相机平移方向,模型的准确率达到了74%-90%,远高于基线模型的约50%。此外,在BLINK基准测试中,该模型的准确率接近90%,远超专有系统。
实际应用
Multi-SpatialMLLM不仅在学术基准上表现出色,在实际应用中也展示了令人印象深刻的能力。例如,研究团队在新收集的机器人手臂堆叠立方体的图像上测试了模型,尽管训练数据中没有包含任何机器人场景,模型仍然能够准确识别静态物体和移动物体。更重要的是,该模型可以作为机器人学习中的“多帧奖励标注器”,通过分析连续帧中物体的移动情况,估计物体的位移距离,为机器人学习提供了一种新的评估方式。
未来展望
尽管这项研究取得了重要突破,但仍有一些局限性。例如,大多数实验仅使用两帧图像,未来研究可以探索使用更多帧的情况,进一步增强空间推理能力。此外,尽管观察到了涌现现象的迹象,但需要更深入的研究来明确哪些具体的空间能力会随着模型规模增加而涌现。未来的研究方向可能包括进一步扩展训练数据规模和模型容量,探索更多帧的空间理解,将模型应用于更多实际场景,如机器人导航、自动驾驶和增强现实,以及深入研究空间理解能力的涌现特性。
总的来说,Multi-SpatialMLLM模型通过整合深度感知、视觉对应和动态感知三大组件,克服了单帧图像分析的局限,为多模态AI在复杂空间任务上的应用开辟了新的可能性。
本网站(https://aigc.izzi.cn)刊载的所有内容,包括文字、图片、音频、视频等均在网上搜集。
访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。除此以外,将本网站任何内容或服务用于其他用途时,须征得本网站及相关权利人的书面许可,并支付报酬。
本网站内容原作者如不愿意在本网站刊登内容,请及时通知本站,予以删除。
上一篇: 《人工智能时代的信仰》
下一篇: ai人工智能工程师