
MIT斯坦福Transformer模型涌现结构泛化能力
发布时间:2023-12-08 21:02:32 | 责任编辑:字母汇 | 浏览量:402 次
斯坦福和MIT的研究人员在最近的研究中发现。
如果对Transformer类的模型进行长时间的训练之后,它能获得这种结构性的泛化能力。
研究人员将这种现象称为:结构顿悟(Structural Grokking,SG)
Grokking这个词是一个作家在书中造出来的词,中文大概翻译成「顿悟」。
微博网友木遥老师把这个词解释为:一个高度复杂的神经网络在漫长的训练期内一直只能记住训练样本的信息,几乎没有泛化能力,但到了某一刻,它的泛化水平忽然跳了出来,而且非常完美。
可以想象成一个神经网络经历了一个「aha moment」,像是内部的某个齿轮忽然对上了一样。

论文地址:https://arxiv.org/abs/2305.18741
研究人员在不同的数据集中发现,SG在模型的深度(Model Depth)上呈现倒U缩放。
中深度模型的泛化能力比非常深和非常浅的模型都要好。
总体上看,如果能对模型进行更多的扩展训练,普通的Transformer能够展现出层级结构。
背景在之前的类似研究中,研究人员认为Transformer在分层级泛化测试中是失败的。
Transformer模型中的分层级结构
为了了解给定的模型是否对获取层次结构有偏见,斯坦福的研究人员按照之前的实验流程,评估了模糊任务上训练的模型的泛化性。
在这些任务中,训练数据与“层次规则”和“非层次规则”相一致的。
为测试是否获得了分层规则,研究人员在一个单独的分布外测试集上测试泛化性。
顿悟(Grokking)
之前的研究表明,在小型算法数据集上会出现顿悟现象,他们发现在训练性能饱和后的很长时间里,模型测试性能继续提高。
因此研究人员就假设存在一个类似的结构顿悟,在域内验证性能饱和后很长时间内,模型对于分层结构依然可以继续顿悟。
因此,分层泛化可以通过扩展训练继续提高。
实验数据集
研究人员的目标是理解transformer中的分层泛化 , 使用了来自之前研究中的两个数据集,并在一个简单的括号跟踪任务上进行了评估。
我们评估了Dyck20,10中结构上未观察到的字符串的泛化能力,以下图为例。

模型
研究人员训练了有{2,4,6,8,10}层的transformer语言模型。
对于每个深度,研究人员用10个随机种子来训练模型,300k steps。(Dyck为400k)
给定输入句子(或在Dyck的情况下前缀),研究人员在测试时从模型中解码。
对于Dyck,研究人员报告准确性是通过在给定语言的输入前缀的情况下,通过对右括号进行排名来生成正确的右括号类型。
和之前已经进行的研究类似,对于Question-Formation,研究人员报告解码问题的第一个单词的准确性。
对于Tense-Inflection,研究人员报告的是目标动词词形变化正确的测试输入的分数。
主要结果Transformers展现出了结构顿悟。
研究人员在下图中展示了在所有数据集上使用最佳模型深度所获得的结果。
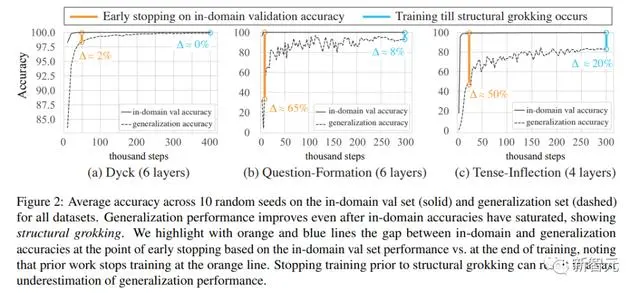
他们发现了明确的结构顿悟证据:在各个数据集上,在分布内准确率饱和之后的训练步骤中,泛化性能得到改善,有时甚至接近完美的准确率。
提前停止是有害的
接下来,研究人员将通过在域内验证准确率上进行提前停止而获得的泛化准确率,与更长的训练流程(如下图)的泛化准确性进行了比较。
提前停止会导致泛化性能被严重低估。
例如,在Question-Formation和Tense-Inflection两个任务上,平均泛化性能从不到40%、不到50%提高到分别不到90%、不到80%。
倒U形分布
在Question-Formation和Tense-Inflection任务中,研究人员从2层到10层逐渐增加深度进行模型训练。
对于每个深度,在下图中报告了最终泛化准确率超过80%的种子数(10个种子中的比例)。
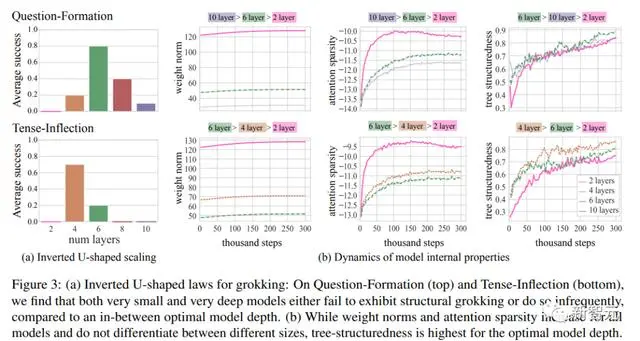
他们发现了一个倒U形的分布状态——非常浅和非常深的模型效果不佳,而大多数种子在中等深度的模型中表现出较好的泛化性能。
这也可以解释为什么之前的研究要么使用非常浅的模型(1-3层的Transformer),要么使用非常深的模型(Mueller等人论文中的12层Transformer),都无法很好地泛化。
分析鉴于结构顿悟仅在一部分模型架构中发生,研究人员能否确定它何时发生(或预测何时会发生)?
几个模型内部属性与结构性理解或Transformer中出现的新兴分层结构或许有关。
Weight Norms
最近的研究将认为参数权重的L2 norm是结构顿悟的重要量。
但总体上来说,训练过程中范数(Norms)增长被作为神经网络泛化的关键因素之一进行了研究。
注意力稀疏性
Merrill等人(2021年)证明了Transformer中的范数增长导致了注意力的饱和,这是新兴语言结构的重要特性(Merrill等人,2022年)。为了衡量fLθ的注意力稀疏性,我们计算了所有分布{apk}的负均熵。
树结构
之前有研究展示了树结构编码器表现出接近完美的分层泛化。
虽然Transformer相对较为自由,但最近的证据表明,当在语言数据上进行训练时,它们隐含地实现了(近似)树结构计算。
而且,之前研究中树投影方法精确地描述了Transformer对输入进行的内部计算可以用树结构神经编码近似的程度,为任何Transformer提供了树结构度量分数(tscore),并提供了一个在输入字符串上最佳近似其计算的二叉树。
为了评估这些树是否与人类的句法概念相对应,我们还将恢复的树与黄金标准树进行比较。
结果在Question-Formation和Tense-Inflection任务中,研究人员通过每隔3k steps更新计算一次这些量的方式来描述权重范数(通过层数统一化来比较不同模型深度)、注意力稀疏性和树结构性的动态变化情况。
对于依赖于数据的属性,如注意力稀疏性和树结构性,我们从训练数据中随机抽取了10k个样例。
研究人员在下图中绘制了这些量在最小模型、最大模型(其中至少有一个运行显示成功的结构顿悟)以及最佳模型深度的情况。
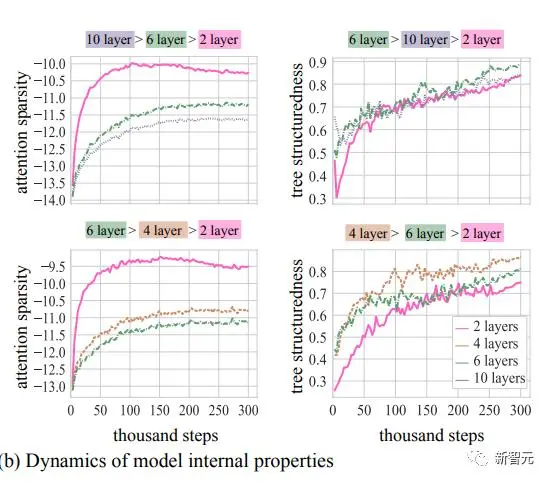
树形结构是最佳的模型
在两个数据集的所有模型设置中,权重范数和注意力稀疏性都会增长。
然而,仅凭这些属性本身无法预测浅层和深层模型的失败 - 浅层模型学习到了最稀疏的解以及具有最大权重范数的解,但从未进行分层泛化。
正如之前的研究中所指出的,tscore随时间的推移对于所有模型都有所改善,表明随着时间的推移,树结构性增加。
对于这两个数据集,与深层和浅层模型相比,“最佳”模型学习到了最多的树结构解。
在算法任务中,结构性理解“与嵌入中结构的出现相吻合”。
类似地,在语言任务中,我们发现结构性理解与树状内部计算的出现相吻合。
Transformer在诱导结构方面表现出惊人的效果
从下图的tparseval的动态变化中,研究人员注意到所有模型,无论它们是否进行泛化,都学习到了接近于真实句法的结构,有时表现优于右分支基线。
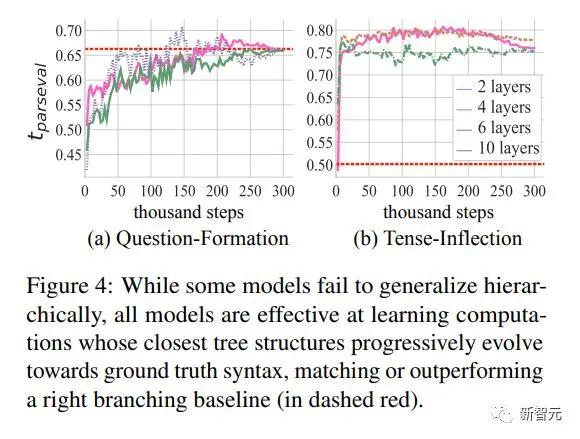
之前的研究认为,只有树结构编码器根据正确的句法分析树进行结构化时才能进行泛化。
研究人员发现所有Transformer都学习到了正确的树结构,但只有最具树结构性的模型表现出最好的泛化能力。
结论这项研究表明,通过结构顿悟机制,Transformer能够展现出对结构敏感的“分层泛化”。
它们的整体学习行为逐渐从记忆(领域内高准确率,领域外准确率较差)向泛化(领域内和领域外准确率高)转变。
虽然研究人员在相对较小的数据集和小型模型上展示了这种行为,但这些结果可能具有更广泛的意义。
因为已经证明长时间的训练即使对于规模庞大的语言建模和组合泛化任务也有帮助。
结构顿悟在“中等规模”的模型深度最常发生,而非常浅和非常深的模型则无法展现出这种行为。
虽然以往与Transformer中的语言泛化相关的属性,如权重范数和注意力稀疏性,不能区分好的架构和坏的架构,但Transformer的功能性树结构可以很好地预测最佳模型深度。
虽然Transformer架构存在一些明显的限制(例如无法实现无限递归),但研究人员的结果表明它可能具有比以前认为的更强的归纳偏好:通过充分的训练,Transformer能够表示分层的句子结构并利用这种结构进行正确的泛化。
参考资料:https://arxiv.org/abs/2305.18741
本网站(https://aigc.izzi.cn)刊载的所有内容,包括文字、图片、音频、视频等均在网上搜集。
访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。除此以外,将本网站任何内容或服务用于其他用途时,须征得本网站及相关权利人的书面许可,并支付报酬。
本网站内容原作者如不愿意在本网站刊登内容,请及时通知本站,予以删除。
上一篇: Transformer模型介绍
下一篇: 值得收藏的五款AI换脸工具