
首页 > 快讯 > 搭建本地deepseek-R1大模型,电脑需要什么配置?
搭建本地deepseek-R1大模型,电脑需要什么配置?
发布时间:2025-03-02 18:12:53 | 责任编辑:字母汇 | 浏览量:1,061 次
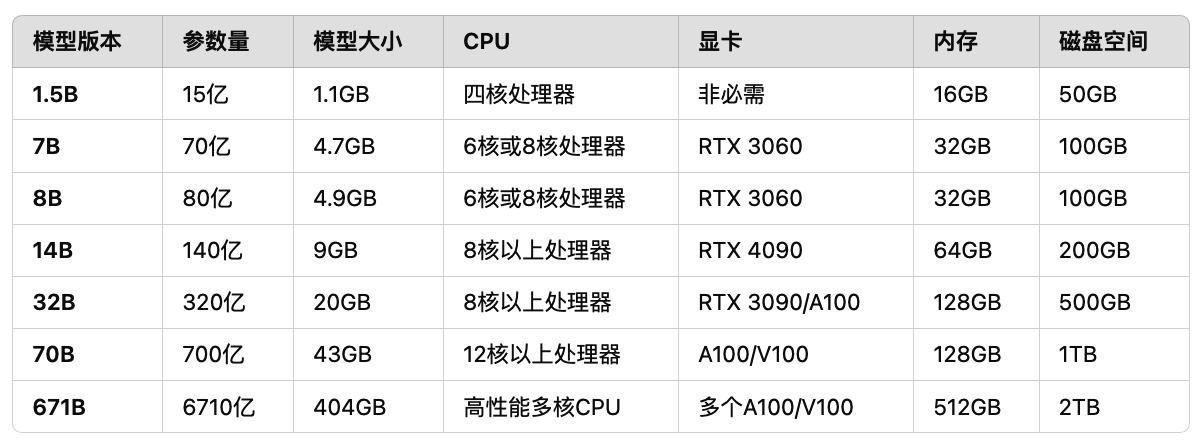
以下是搭建本地 DeepSeek-R1 大模型 的推荐电脑配置表,结合模型参数规模与硬件需求对应关系整理:
DeepSeek-R1 模型配置表
| 模型版本 | 参数量 | 模型大小 | CPU 要求 | 显卡要求 | 内存要求 | 磁盘空间 |
|---|---|---|---|---|---|---|
| 1.5B | 15亿 | 1.1GB | 四核处理器 | 非必需 | 16GB | 50GB |
| 7B | 70亿 | 4.7GB | 6核或8核处理器 | RTX 3060 (12GB) | 32GB | 100GB |
| 14B | 140亿 | 9GB | 8核以上处理器 | RTX 4090 (24GB) | 64GB | 200GB |
| 32B | 320亿 | 20GB | 8核以上处理器 | RTX 3090/A100 (24GB+/40GB) | 128GB | 500GB |
| 70B | 700亿 | 43GB | 12核以上处理器 | A100/V100 (多卡) | 128GB | 1TB |
| 671B | 6710亿 | 404GB | 高性能多核服务器CPU | 多张A100/H100集群 | 512GB | 2TB |
分场景配置推荐
1. 入门级(7B以下模型)
- 场景:文本生成、对话等轻量任务。
- 显卡:RTX 3060 12GB(单卡)或无需显卡(纯CPU推理)。
- 内存:32GB DDR4。
- 存储:100GB NVMe SSD(建议预留双倍空间)。
- 优化:使用4-bit量化可将显存需求降低至4-6GB。
2. 高性能级(14B-70B模型)
- 场景:复杂推理、多轮对话、代码生成。
- 显卡:RTX 4090(24GB)或单卡A100(40GB)。
- 内存:64GB-128GB DDR5。
- 存储:500GB-1TB NVMe SSD(高速读写缓存)。
- 关键点:需开启混合精度(FP16/BF16)以节省显存。
3. 企业级(70B以上模型)
- 场景:千亿参数训练、大规模微调。
- 显卡:多卡A100/H100(通过NVLink互联)。
- 内存:256GB+ ECC DDR5。
- 存储:2TB+ RAID 0 NVMe SSD阵列。
- 网络:InfiniBand高速互联(分布式训练必备)。
关键配置说明
- 显存计算
- 全精度(FP32):显存 ≈ 参数量 × 4字节(如14B模型需约56GB显存)。
- 半精度(FP16):显存减半(14B模型需28GB,需RTX 4090或A100)。
- 量化方案:4-bit量化后,显存仅需全精度的1/4(14B模型仅需7GB)。
- 多卡配置
- 70B以上模型需多卡并行(如2-4张A100 80GB),通过
DeepSpeed或vLLM框架优化显存分配。
- 70B以上模型需多卡并行(如2-4张A100 80GB),通过
- CPU与内存
- CPU核心数需匹配数据预处理需求(建议8核以上),内存容量建议≥模型大小的3倍(如70B模型需128GB)。
- 系统与软件
- 推荐Ubuntu系统(对多GPU支持更佳),安装CUDA 12+、PyTorch 2.0+、NVIDIA驱动535+。
性价比方案示例
- 目标模型:14B
- 显卡:RTX 4090(24GB,半精度直接运行)
- CPU:AMD Ryzen 9 7950X(16核)
- 内存:64GB DDR5
- 存储:1TB NVMe SSD
- 总成本:约2.5万-3万元(人民币)。
建议根据具体模型版本选择配置,并优先通过量化技术(如GGUF、GPTQ)降低硬件门槛。此外,蒸馏版模型通过量化技术降低了硬件门槛,适用于资源有限的环境。因此,选择合适的模型版本应根据实际需求和硬件配置进行权衡。
©️版权声明:
本网站(https://aigc.izzi.cn)刊载的所有内容,包括文字、图片、音频、视频等均在网上搜集。
访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。除此以外,将本网站任何内容或服务用于其他用途时,须征得本网站及相关权利人的书面许可,并支付报酬。
本网站内容原作者如不愿意在本网站刊登内容,请及时通知本站,予以删除。
本网站(https://aigc.izzi.cn)刊载的所有内容,包括文字、图片、音频、视频等均在网上搜集。
访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。除此以外,将本网站任何内容或服务用于其他用途时,须征得本网站及相关权利人的书面许可,并支付报酬。
本网站内容原作者如不愿意在本网站刊登内容,请及时通知本站,予以删除。