
Kimi K2 发布并开源,擅长代码与 Agentic 任务
发布时间:2025-07-12 00:11:36 | 责任编辑:字母汇 | 浏览量:774 次
《Kimi K2 发布并开源,擅长代码与 Agentic 任务》相关软件官网
2025年7月11日正式发布 Kimi K2 模型,并同步开源。
Kimi K2 是一款具备更强代码能力、更擅长通用 Agent 任务的 MoE 架构基础模型,总参数 1T,激活参数 32B。

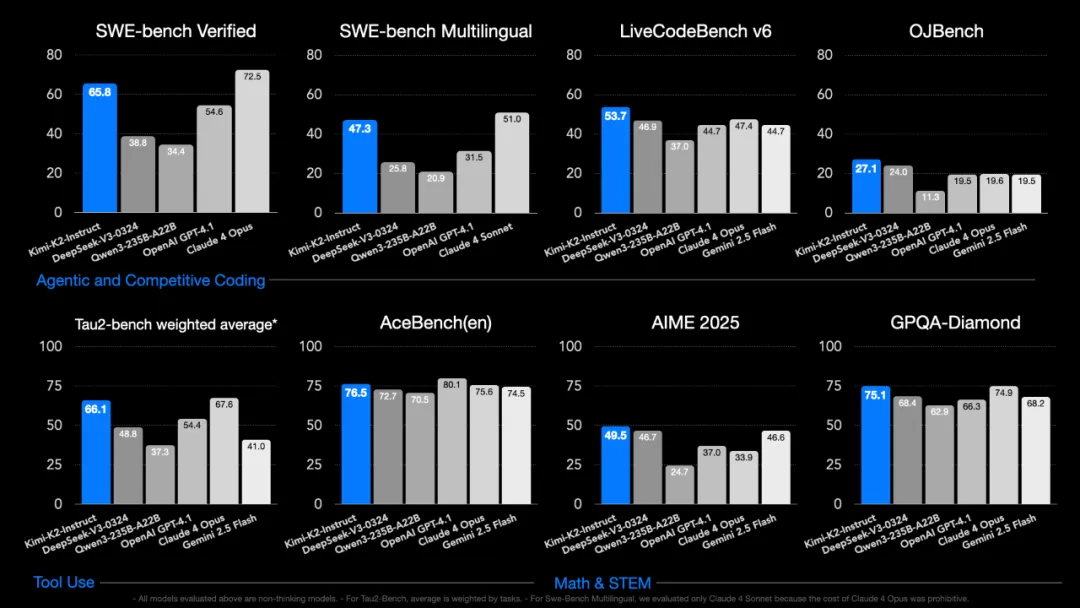
在 SWE Bench Verified、Tau2、AceBench 等基准性能测试中,Kimi K2 均取得开源模型中的 SOTA 成绩,展现出在代码、Agent、数学推理任务上的领先能力。
Kimi K2 的预训练阶段使用 MuonClip 优化器实现万亿参数模型的稳定高效训练,在人类高质量数据成为瓶颈的背景下,有效提高 Token 利用效率,找到新的 Scaling 空间。
其他关键技术包括大规模 Agentic Tool Use 数据合成和引入自我评价机制的通用强化学习等,更多细节,可参考我们的技术博客。
即日起,访问官网 kimi.com 或下载 Kimi App,即可体验全新 Kimi K2 模型;API 服务也已同步上线,提供兼容 OpenAI 和 Anthropic 的 Chat API 接口,你可以轻松将常用的大模型工具切换至 Kimi K2,体验强大的 Agent/Coding 能力。
Kimi K2 是构建通用 Agent 能力的坚实基础,但通用 Agent 还需要更高级的能力,比如思考和视觉理解。我们计划未来为 Kimi K2 加入这些能力。
我们希望通过全面开源性能更强的模型,进一步加速 AGI 研究与应用落地的整体进程。
模型性能提升
Kimi K2 在自主编程(Agentic Coding)、工具调用(Tool Use)和数学推理(Math & Reasoning)三大能力维度的基准性能测试中取得优秀表现。
除了基准性能测试,Kimi K2 在多个实际场景中也展现出更强的能力泛化和实用性:
代码能力提升
在前端开发任务中,Kimi K2 擅长生成兼具设计感与视觉表现力的代码,支持粒子系统、可视化和 3D 场景等表现形式,具备较强的图形能力与交互性。
Agent 工具调用能力提升
Kimi K2 现已具备稳定的复杂指令解析能力,可将需求自动拆解为一系列格式规范、可直接执行的 ToolCall 结构。
你可以将其无缝接入 owl、Cline、RooCode 等 Agent/Coding 框架,完成复杂任务或自动化编码。
风格化写作能力提升
在改写任务中,Kimi K2 能准确控制输出风格,无论是用初中生语气改写科研文本,还是模仿苹果广告文案,都能同时保留原意与表达风格,体现较强的语境保持和表达迁移能力。
此外,Kimi K2 在通用知识推理、数学、规划等任务中的表现亦有提升。
上线即开源
我们同步开源了 Kimi K2 系列中的两个模型版本:
Kimi-K2-Base:未经过指令微调的基础预训练模型,适合科研与自定义场景;
Kimi-K2-Instruct:通用指令微调版本(非思考模型),在大多数问答与 Agent 任务中表现卓越。
模型及 fp8 权重文件已开源至 Hugging Face
此外,vLLM、SGLang、ktransformers 等推理引擎也已经同步支持,你可以用自己的服务器部署获得 Kimi 开放平台 API 相同的体验。
技术探索
Kimi K2 用 MuonClip 优化器稳健支撑万亿参数模型训练,显著提升 token 利用效率。 结合大规模 Agentic 数据合成与通用强化学习,模型在通用智能能力上持续进展。
MuonClip 优化器:Kimi K2抛弃了传统的Adam优化器,创新性的使用了Muon优化器。为了缓解大规模训练中的attention logits偏大问题,我们提出 MuonClip,并将其扩展到万亿参数规模,提升了训练稳定性和 token 使用效率。Kimi K2 完成了 15.5T token 的平稳训练,全程无 loss spike。
大规模 Agentic Tool Use 数据合成:我们构建了可大规模生成多轮工具使用场景的合成 pipeline,覆盖数百领域、数千工具。高质量样本由 LLM 评估筛选后用于训练。
通用强化学习:Kimi K2 不仅在可验证任务上(代码、数学)强化学习,还通过引入自我评价机制(self-judging),解决了不可验证任务的奖励稀缺问题。通过可验证任务持续优化 critic,提升泛化任务表现。
API 及定价
Kimi K2 的 API 服务现已全面上线,支持最长 128K 上下文,具备更强的通用性与工具调用能力。计费方案如下:
每百万输入 tokens:4 元
每百万输出 tokens:16 元
我们兼容 OpenAI 和 Anthropic 两种 API 格式,也可以与各类框架良好兼容。此外,全新升级的 ToolCall 能力,可以严格保障格式正确性,适用于复杂 Agent 任务。
模型介绍
Kimi K2 是一款先进的混合专家 (MoE) 语言模型,拥有 320 亿个激活参数和 1 万亿个总参数。Kimi K2 采用 Muon 优化器进行训练,在前沿知识、推理和编码任务中表现出色,同时针对代理能力进行了精心优化。
主要特点
- 大规模训练:在 15.5T 令牌上预先训练 1T 参数 MoE 模型,且训练不稳定性为零。
- MuonClip 优化器:我们将 Muon 优化器应用于前所未有的规模,并开发新的优化技术来解决扩展过程中的不稳定性问题。
- 代理智能:专为工具使用、推理和自主解决问题而设计。
模型变体
- Kimi-K2-Base:基础模型,对于想要完全控制微调和定制解决方案的研究人员和建设者来说是一个强有力的开端。
- Kimi-K2-Instruct:后训练模型,最适合用于即兴、通用聊天和代理体验。它是一款无需长时间思考的反射级模型。
模型总结
| 建筑学 | 混合专家(MoE) |
| 总参数 | 1吨 |
| 激活的参数 | 32B |
| 层数(包括密集层) | 61 |
| 密集层的数量 | 1 |
| 注意力隐藏维度 | 7168 |
| MoE 隐藏维度(每位专家) | 2048 |
| 注意力头数量 | 64 |
| 专家人数 | 384 |
| 每个代币选定的专家 | 8 |
| 共享专家数量 | 1 |
| 词汇量 | 16万 |
| 上下文长度 | 128千 |
| 注意力机制 | MLA |
| 激活函数 | 斯威格鲁 |
评估结果
教学模型评估结果
| 基准 | 公制 | Kimi K2 指导 | DeepSeek-V3-0324 | Qwen3-235B-A22B (无思维) |
克劳德十四行诗 4 (无延伸思考) |
克劳德作品 4 (无延伸思考) |
GPT-4.1 | Gemini 2.5 Flash 预览 (05-20) |
|---|---|---|---|---|---|---|---|---|
| 编码任务 | ||||||||
| LiveCodeBench v6 (8 月 24 日 - 5 月 25 日) |
通行证@1 | 53.7 | 46.9 | 37.0 | 48.5 | 47.4 | 44.7 | 44.7 |
| OJBench | 通行证@1 | 27.1 | 24.0 | 11.3 | 15.3 | 19.6 | 19.5 | 19.5 |
| 多种的 | 通行证@1 | 85.7 | 83.1 | 78.2 | 88.6 | 89.6 | 86.7 | 85.6 |
| SWE-bench 验证 (无代理编码) |
单贴片,无需测试(Acc) | 51.8 | 36.6 | 39.4 | 50.2 | 53.0 | 40.8 | 32.6 |
| SWE-bench 验证 (代理编码) |
单次尝试(累计) | 65.8 | 38.8 | 34.4 | 72.7 * | 72.5 * | 54.6 | — |
| 多次尝试(累计) | 71.6 | — | — | 80.2 | 79.4 * | — | — | |
| SWE-bench 多语言 (代理编码) |
单次尝试(累计) | 47.3 | 25.8 | 20.9 | 51.0 | — | 31.5 | — |
| 终端台 | 内部框架(Acc) | 30.0 | — | — | 35.5 | 43.2 | 8.3 | — |
| 终点站(Acc) | 25.0 | 16.3 | 6.6 | — | — | 30.3 | 16.8 | |
| 辅助多语言者 | 账户 | 60.0 | 55.1 | 61.8 | 56.4 | 70.7 | 52.4 | 44.0 |
| 工具使用任务 | ||||||||
| Tau2零售 | 平均@4 | 70.6 | 69.1 | 57.0 | 75.0 | 81.8 | 74.8 | 64.3 |
| Tau2航空公司 | 平均@4 | 56.5 | 39.0 | 26.5 | 55.5 | 60.0 | 54.5 | 42.5 |
| Tau2电信 | 平均@4 | 65.8 | 32.5 | 22.1 | 45.2 | 57.0 | 38.6 | 16.9 |
| AceBench | 账户 | 76.5 | 72.7 | 70.5 | 76.2 | 75.6 | 80.1 | 74.5 |
| 数学和 STEM 任务 | ||||||||
| 2024年国际微电子展览会 | 平均@64 | 69.6 | 59.4 * | 40.1 * | 43.4 | 48.2 | 46.5 | 61.3 |
| 2025年国际医疗设备展览会 | 平均@64 | 49.5 | 46.7 | 24.7 * | 33.1 * | 33.9 * | 37.0 | 46.6 |
| 数学-500 | 账户 | 97.4 | 94.0 * | 91.2 * | 94.0 | 94.4 | 92.4 | 95.4 |
| HMMT 2025 | 平均@32 | 38.8 | 27.5 | 11.9 | 15.9 | 15.9 | 19.4 | 34.7 |
| 2024年中国移动大会 | 平均@16 | 74.3 | 74.7 | 48.6 | 60.4 | 57.6 | 56.6 | 75.0 |
| 波利马森 | 平均@4 | 65.1 | 59.5 | 51.9 | 52.8 | 49.8 | 54.0 | 49.9 |
| 斑马逻辑 | 账户 | 89.0 | 84.0 | 37.7 * | 73.7 | 59.3 | 58.5 | 57.9 |
| AutoLogi | 账户 | 89.5 | 88.9 | 83.3 | 89.8 | 86.1 | 88.2 | 84.1 |
| GPQA-钻石 | 平均@8 | 75.1 | 68.4 * | 62.9 * | 70.0 * | 74.9 * | 66.3 | 68.2 |
| 超级GPQA | 账户 | 57.2 | 53.7 | 50.2 | 55.7 | 56.5 | 50.8 | 49.6 |
| 人类的最后考试 (纯文本) |
- | 4.7 | 5.2 | 5.7 | 5.8 | 7.1 | 3.7 | 5.6 |
| 常规任务 | ||||||||
| 默多克大学 | 电磁波 | 89.5 | 89.4 | 87.0 | 91.5 | 92.9 | 90.4 | 90.1 |
| MMLU-Redux | 电磁波 | 92.7 | 90.5 | 89.2 | 93.6 | 94.2 | 92.4 | 90.6 |
| MMLU-Pro | 电磁波 | 81.1 | 81.2* | 77.3 | 83.7 | 86.6 | 81.8 | 79.4 |
| 评估 | 提示严格 | 89.8 | 81.1 | 83.2 * | 87.6 | 87.4 | 88.0 | 84.3 |
| 多重挑战 | 账户 | 54.1 | 31.4 | 34.0 | 46.8 | 49.0 | 36.4 | 39.5 |
| 简单问答 | 正确的 | 31.0 | 27.7 | 13.2 | 15.9 | 22.8 | 42.3 | 23.3 |
| Livebench | 通行证@1 | 76.4 | 72.4 | 67.6 | 74.8 | 74.6 | 69.8 | 67.8 |
• 粗体表示全球 SOTA,下划线表示开源 SOTA。
• 标有 * 的数据点直接取自模型的技术报告或博客。
• 除 SWE-bench Verified (Agentless) 外,所有指标均以 8k 输出令牌长度进行评估。SWE-bench Verified (Agentless) 的输出令牌长度限制为 16k。
• Kimi K2 使用 bash/editor 工具(单次尝试补丁,无测试时计算)在 SWE-bench Verified 测试中实现了 65.8% 的 pass@1。在相同条件下,它还在 SWE-bench Multilingual 测试中实现了 47.3% 的 pass@1。此外,我们报告了 SWE-bench Verified 测试(71.6%)的结果,该测试通过对多个序列进行采样并通过内部评分模型选择最佳序列来利用并行测试时计算。
• 为确保评估的稳定性,我们在 AIME、HMMT、CNMO、PolyMath-en、GPQA-Diamond、EvalPlus、Tau2 上采用了 avg@k。
由于评估成本过高,一些数据点已被省略。
基础模型评估结果
| 基准 | 公制 | 射击 | Kimi K2 基地 | Deepseek-V3-Base | Qwen2.5-72B | 骆驼 4 特立独行 |
|---|---|---|---|---|---|---|
| 常规任务 | ||||||
| 默多克大学 | 电磁波 | 5发 | 87.8 | 87.1 | 86.1 | 84.9 |
| MMLU-pro | 电磁波 | 5发 | 69.2 | 60.6 | 62.8 | 63.5 |
| MMLU-redux-2.0 | 电磁波 | 5发 | 90.2 | 89.5 | 87.8 | 88.2 |
| 简单问答 | 正确的 | 5发 | 35.3 | 26.5 | 10.3 | 23.7 |
| 琐事问答 | 电磁波 | 5发 | 85.1 | 84.1 | 76.0 | 79.3 |
| GPQA-钻石 | 平均@8 | 5发 | 48.1 | 50.5 | 40.8 | 49.4 |
| 超级GPQA | 电磁波 | 5发 | 44.7 | 39.2 | 34.2 | 38.8 |
| 编码任务 | ||||||
| LiveCodeBench v6 | 通行证@1 | 1次射击 | 26.3 | 22.9 | 21.1 | 25.1 |
| EvalPlus | 通行证@1 | - | 80.3 | 65.6 | 66.0 | 65.5 |
| 数学任务 | ||||||
| 数学 | 电磁波 | 4发 | 70.2 | 60.1 | 61.0 | 63.0 |
| GSM8k | 电磁波 | 8发 | 92.1 | 91.7 | 90.4 | 86.3 |
| 中文任务 | ||||||
| C-评估 | 电磁波 | 5发 | 92.5 | 90.0 | 90.9 | 80.9 |
| CSimpleQA | 正确的 | 5发 | 77.6 | 72.1 | 50.5 | 53.5 |
• 本研究仅评估开源预训练模型。我们报告 Qwen2.5-72B 的结果,因为 Qwen3-235B-A22B 的基础检查点在我们研究时尚未开源。
• 所有模型均使用相同的评估协议进行评估。
本网站(https://aigc.izzi.cn)刊载的所有内容,包括文字、图片、音频、视频等均在网上搜集。
访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。除此以外,将本网站任何内容或服务用于其他用途时,须征得本网站及相关权利人的书面许可,并支付报酬。
本网站内容原作者如不愿意在本网站刊登内容,请及时通知本站,予以删除。